
#genocon2021b. [genocon2021_b]Practice 2
[genocon2021_b]Practice 2
問題文
とは文字A, C, G, Tからなる文字列である. との 番目の文字はそれぞれ,s\[i\] ,t\[i\]と記述する.ここで,との適当な位置に空白を表す文字 - を挿入して長さをそろえ,Sum of pairsと呼ばれる次のスコアを最大化することを考える.
= sim(s\[i\], t\[i\])
ただし,は - を挿入後の文字列の長さとする.また,はとの類似度を示す関数であり,その入出力は以下の表で与えられるものとする.
\
A
C
G
T
-
A
1
-3
-3
-3
-5
C
-3
1
-3
-3
-5
G
-3
-3
1
-3
-5
T
-3
-3
-3
1
-5
-
-5
-5
-5
-5
-5
例えば,=CTCGGT,=CATCCの場合,の1文字目の後に - を一つ,の5文字目の後に - を二つ挿入すれば,
= C, C-,AT,TC,CG,CG,-T,-
のように計算することができ,が最大となる. この時,- を挿入したとを次のように上下に並べてみると,上下の同じ位置に(なるべく)同じ文字が現れるようにとがそろう.
C-TCGGT
CATCC--
このように,文字列中の適切な場所に空白 - を挿入して二本の文字列をそろえることをペアワイズアラインメントと呼ぶ.
二本の入力文字列についてを最大化するペアワイズアラインメントを出力せよ.
制約
- とはA, C, G, Tからなる文字列である.
- (文字列の長さをと記述する.)
入力
入力は以下の形式で標準入力から与えられる.
出力
入力文字列のが最大となるペアワイズアラインメントを出力せよ.例に倣い,との適切な位置に - を挿入した後,一行目には,二行目にはを出力すること. が最大となるアラインメントが複数存在する場合は,いずれか一つを任意に選択して出力すること. 一行目と二行目は同じ長さでなければならない.また,一行目から-を除いた文字列はと一致していなければならない.同様に,二行目も-を除いた文字列はと一致していなければならない.
入力例 1
AGTTGAATTT
GTCGGACTTT
出力例 1
AGT-TGAATTT
-GTCGGACTTT
問題の背景
※ この項目は読まなくても問題を解くことができますが,出題の背景となりますため,ご興味を持ってくださった方はお読みいただけると幸いです.
ペアワイズアラインメントはゲノム配列解析の様々な場面において用いられます.ここでは,個人のゲノム配列解析について考えてみたいと思います.
DNAからゲノム配列を読み出す装置をシークエンサーと呼びます.ヒトのゲノム配列は全長30億塩基に及ぶ非常に長い配列ですが,シークエンサーはこの長い配列を端から端まで一気に読み出せるわけではありません.装置によって読み出しの長さは異なりますが,短いもので数百,長いもので数百万塩基程度の断片を読み出すのです.ですから,読み取った断片配列がゲノム上のどの部分に相当するのか突き止めなければなりません.そこで,既に決定されているヒトの標準的なゲノム配列(参照ゲノム配列と呼ぶ)と見比べて,読み取った断片配列の位置を特定するのです.ここで注意しなければならないのは,読み出した断片配列とそれに対応する参照ゲノムの部分配列には違いがあるという点です.差異が生じる理由は二つあります.一つは,ゲノム配列は個人(個体)ごとに少しずつ異なるためで,もう一つはシークエンサーがゲノム配列を読み出す際にエラーを発生させてしまうためです.これら二つに共通するのは,参照ゲノム配列に対して次のような差異が比較的多く生じるということです.
置換(ある文字が別の文字に置き換わっている.)
ATGC ← 参照ゲノム配列
ATCC ← 読み出した個人のゲノム配列
欠損(ある文字が欠損している.)
ATGC ← 参照ゲノム配列
AT-C ← 読み出した個人のゲノム配列
挿入(ある文字が追加されている.)
ATC-C ← 参照ゲノム配列
ATCAC ← 読み出した個人のゲノム配列
このような差異のある配列同士の類似部分をうまく並べるために,ペアワイズアラインメントが必要となるのです. なお,ゲノム配列全長とシークエンサーで読み出した断片配列のように長さが大きく違う配列をアラインメントするには様々な工夫が必要となります.また,良いアラインメントを作るためには類似度の設計も重要です.例えば,挿入があまり入らないと予想されるケースでは-と別の文字の類似度をより低くする必要があるでしょう.上記のでは,文字の不一致(置換)には同じ類似度を与えていましたが,置換が起きやすい文字の間の類似度を高くするなどの工夫も考えられます.
シークエンサーについて
さて,上の文章で書いた「個人のゲノム配列解析」が気軽にできるようになったのは,実はごく最近のことなのです.次のグラフをご覧ください.(NIHより引用)
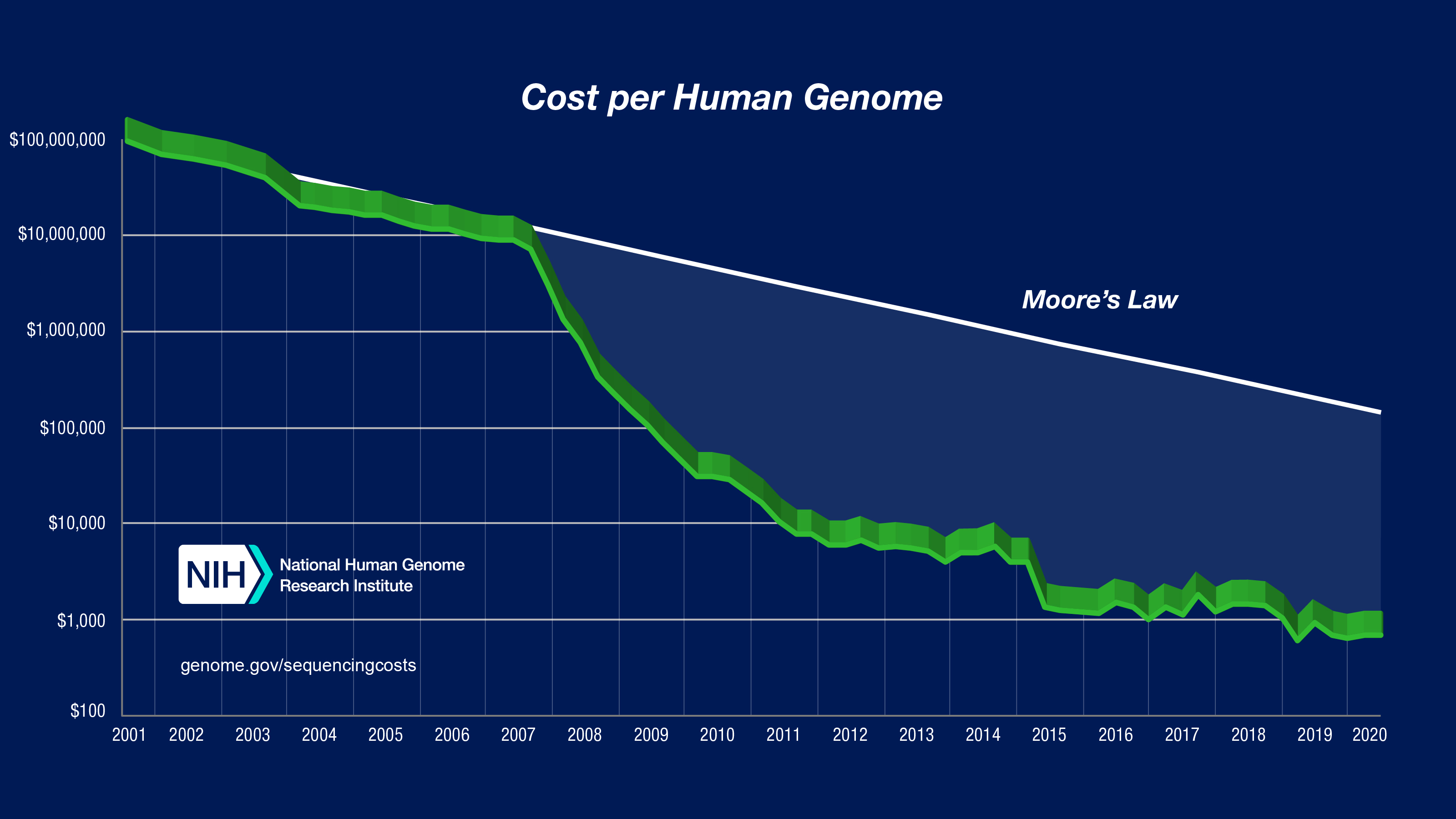
こちらは,アメリカ国立衛生研究所(National Institute of Health)が試算した一人分のヒトゲノムを読みとるのに必要な金額を示したグラフです.縦軸がコスト,横軸が年を示しています.現在の読み取り費用は約10万円ですが,20年前はなんと100億円必要だったのです.グラフを見ると,2000年代後半から急激にコストが下落しているのがわかると思います.一体,何が起きたのでしょうか?
実は,上述の「シークエンサー」に技術革新が起き,読み取り(シークエンシングと呼びます)コストが劇的に下がったのです.シークエンサーの性能向上は,生命科学の研究を大きく前進させました.そして同時に,同分野における計算機科学の重要性も大きく高めることになったのです.考えてみてください,個人の設計図が10万円で手に入るのです.世界中の研究機関では膨大なデータが算出されます.各設計図は30億塩基対に及ぶ大きさで,シークエンサーは設計図の断片を(多少のエラーを含めながら)大量,かつバラバラに読み出してくるのです.優れたアルゴリズムなくして解析を遂行することはできません.
シークエンサーの性能向上は日進月歩のため,その出力データを解析するアルゴリズムにも日進月歩の向上が求められています.D問題で使うデータは,Oxford Nanopore Technologies社のシークエンサーによるものです.こちらは,読み取り長がとても長いという優れた特徴を持ち,多くの解析の現場で用いられています.今回は,最新のキットQ20を用いて読み出したデータとなることにもご注目ください.